Why do we need cache/persist?
Let's walk through an example
The flow is simple:
- Read sales.csv and generate
sales_df - Add a column
value_flagtosales_df, to generatesales_base_df - Filter
sales_base_dfto generatehigh_value_sales_df - Filter
sales_base_dfto generatelow_value_sales_df
So, your expected lineage after execution is:
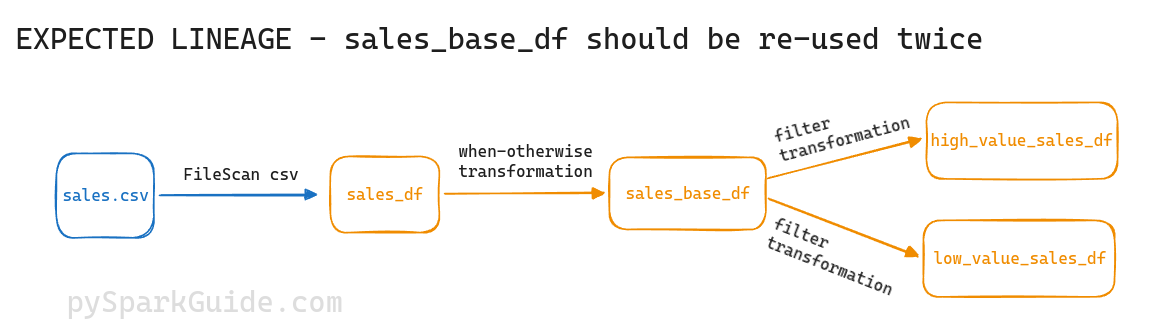 This doesn't happen in reality. Let's check it out.
This doesn't happen in reality. Let's check it out.
# ################################
# 1. Read sales.csv and generate sales_df
sales_df = (
spark
.read
.format("csv")
.option("header", "true")
.load("/home/jovyan/data/sales.csv")
)
# ################################
# 2. Add a column to sales_df and generate sales_base_df
sales_base_df = sales_df.withColumn(
"value_flag",
F.when(F.col("amount") < 200, "low_value")
.when((F.col("amount") >= 200) & (F.col("amount") < 300), "medium_value")
.when(F.col("amount") >= 300, "high_value")
.otherwise(None),
)
print("sales_df PHYSICAL PLAN ================================")
sales_df.explain(mode='simple')
# ################################
# 3. Filter sales_base_df and generate high_value_sales_df
high_value_sales = sales_base_df.filter(F.col("value_flag")=='high_value')
print("high_value_sales PHYSICAL PLAN ================================")
high_value_sales.explain(mode='simple')
# ################################
# 4. Filter sales_base_df and generate low_value_sales
low_value_sales = sales_base_df.filter(F.col("value_flag")=='low_value')
print("low_value_sales PHYSICAL PLAN ================================")
low_value_sales.explain(mode='simple')
The execution plan output is:
sales_base_df PHYSICAL PLAN ================================
== Physical Plan ==
*(1) Project [Name#17, City#18, Amount#19, CASE WHEN (cast(amount#19 as int) < 200) THEN low_value WHEN ((cast(amount#19 as int) >= 200) AND (cast(amount#19 as int) < 300)) THEN medium_value WHEN (cast(amount#19 as int) >= 300) THEN high_value END AS value_flag#40]
+- FileScan csv [Name#17,City#18,Amount#19] Batched: false, DataFilters: [], Format: CSV, Location: InMemoryFileIndex(1 paths)[file:/home/jovyan/data/sales.csv], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<Name:string,City:string,Amount:string>
high_value_sales PHYSICAL PLAN ================================
== Physical Plan ==
*(1) Project [Name#17, City#18, Amount#19, CASE WHEN (cast(amount#19 as int) < 200) THEN low_value WHEN ((cast(amount#19 as int) >= 200) AND (cast(amount#19 as int) < 300)) THEN medium_value WHEN (cast(amount#19 as int) >= 300) THEN high_value END AS value_flag#40]
+- *(1) Filter CASE WHEN (cast(amount#19 as int) < 200) THEN false WHEN ((cast(amount#19 as int) >= 200) AND (cast(amount#19 as int) < 300)) THEN false WHEN (cast(amount#19 as int) >= 300) THEN true ELSE false END
+- FileScan csv [Name#17,City#18,Amount#19] Batched: false, DataFilters: [CASE WHEN (cast(Amount#19 as int) < 200) THEN false WHEN ((cast(Amount#19 as int) >= 200) AND (c..., Format: CSV, Location: InMemoryFileIndex(1 paths)[file:/home/jovyan/data/sales.csv], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<Name:string,City:string,Amount:string>
low_value_sales PHYSICAL PLAN ================================
== Physical Plan ==
*(1) Project [Name#17, City#18, Amount#19, CASE WHEN (cast(amount#19 as int) < 200) THEN low_value WHEN ((cast(amount#19 as int) >= 200) AND (cast(amount#19 as int) < 300)) THEN medium_value WHEN (cast(amount#19 as int) >= 300) THEN high_value END AS value_flag#40]
+- *(1) Filter CASE WHEN (cast(amount#19 as int) < 200) THEN true WHEN ((cast(amount#19 as int) >= 200) AND (cast(amount#19 as int) < 300)) THEN false WHEN (cast(amount#19 as int) >= 300) THEN false ELSE false END
+- FileScan csv [Name#17,City#18,Amount#19] Batched: false, DataFilters: [CASE WHEN (cast(Amount#19 as int) < 200) THEN true WHEN ((cast(Amount#19 as int) >= 200) AND (ca..., Format: CSV, Location: InMemoryFileIndex(1 paths)[file:/home/jovyan/data/sales.csv], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<Name:string,City:string,Amount:string>
Look at the FileScan in the execution plans of both high_value_sales and low_value_sales.
It means that to generate these dataframes, spark is reading the csv file again and again, and re-calculating all the dataframes along the way.
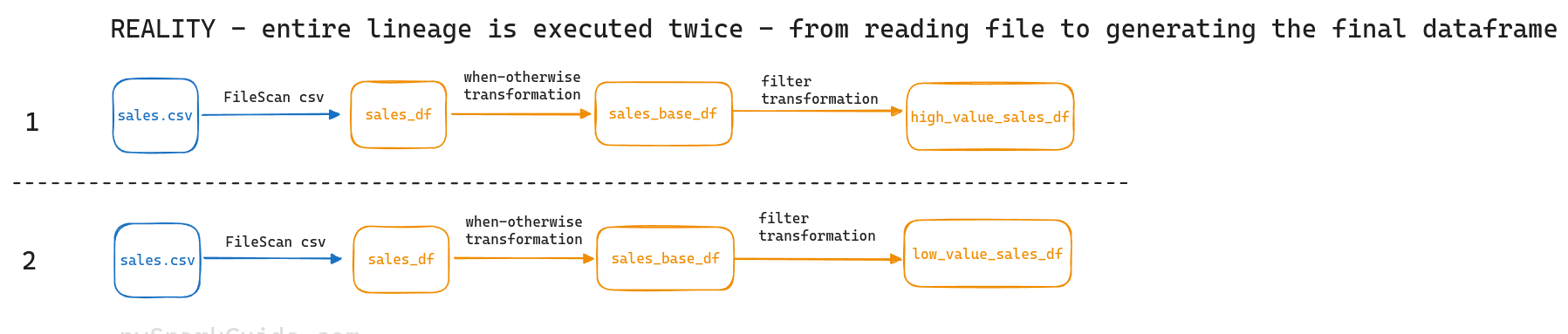 Spark didn't re-use anything. For both
Spark didn't re-use anything. For both high_value_sales_df and low_value_sales_df, it executed the entire lineage from the beginning itself.
It re-calculated sales_base_df twice. It executed the part from reading sales.csv till generating sales_base_df twice. This is horribly inefficient.
Solution - use cache() or persist()
Let's tell spark to cache() the salesbasedf.
The code is the same. I've just added a caching step in the middle.
sales_df = (
spark
.read
.format("csv")
.option("header", "true")
.load("/home/jovyan/data/sales.csv")
)
sales_base_df = sales_df.withColumn(
"value_flag",
F.when(F.col("amount") < 200, "low_value")
.when((F.col("amount") >= 200) & (F.col("amount") < 300), "medium_value")
.when(F.col("amount") >= 300, "high_value")
.otherwise(None),
)
# ################################
sales_base_df.cache() # CACHE sales_base_df TO MEMORY ####
# ################################
high_value_sales = sales_base_df.filter(F.col("value_flag")=='high_value')
print("high_value_sales PHYSICAL PLAN ================================")
high_value_sales.explain(mode='simple')
low_value_sales = sales_base_df.filter(F.col("value_flag")=='low_value')
print("low_value_sales PHYSICAL PLAN ================================")
low_value_sales.explain(mode='simple')
Now, the execution plan output is:
DataFrame[Name: string, City: string, Amount: string, value_flag: string]
high_value_sales PHYSICAL PLAN ================================
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- Filter (isnotnull(value_flag#45) AND (value_flag#45 = high_value))
+- InMemoryTableScan [Name#17, City#18, Amount#19, value_flag#45], [isnotnull(value_flag#45), (value_flag#45 = high_value)]
+- InMemoryRelation [Name#17, City#18, Amount#19, value_flag#45], StorageLevel(disk, memory, deserialized, 1 replicas)
+- *(1) Project [Name#17, City#18, Amount#19, CASE WHEN (cast(amount#19 as int) < 200) THEN low_value WHEN ((cast(amount#19 as int) >= 200) AND (cast(amount#19 as int) < 300)) THEN medium_value WHEN (cast(amount#19 as int) >= 300) THEN high_value END AS value_flag#45]
+- FileScan csv [Name#17,City#18,Amount#19] Batched: false, DataFilters: [], Format: CSV, Location: InMemoryFileIndex(1 paths)[file:/home/jovyan/data/sales.csv], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<Name:string,City:string,Amount:string>
low_value_sales PHYSICAL PLAN ================================
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- Filter (isnotnull(value_flag#45) AND (value_flag#45 = low_value))
+- InMemoryTableScan [Name#17, City#18, Amount#19, value_flag#45], [isnotnull(value_flag#45), (value_flag#45 = low_value)]
+- InMemoryRelation [Name#17, City#18, Amount#19, value_flag#45], StorageLevel(disk, memory, deserialized, 1 replicas)
+- *(1) Project [Name#17, City#18, Amount#19, CASE WHEN (cast(amount#19 as int) < 200) THEN low_value WHEN ((cast(amount#19 as int) >= 200) AND (cast(amount#19 as int) < 300)) THEN medium_value WHEN (cast(amount#19 as int) >= 300) THEN high_value END AS value_flag#45]
+- FileScan csv [Name#17,City#18,Amount#19] Batched: false, DataFilters: [], Format: CSV, Location: InMemoryFileIndex(1 paths)[file:/home/jovyan/data/sales.csv], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<Name:string,City:string,Amount:string>
Notice the InMemoryTableScan in the plans of high_value_sales and low_value_sales. It means that spark is reading the sales_base_df we cached into memory. And not re-calculating all the dataframes from scratch. It is not re-calculating the sales_base_df. It is simply re-using the sales_base_df we cached.
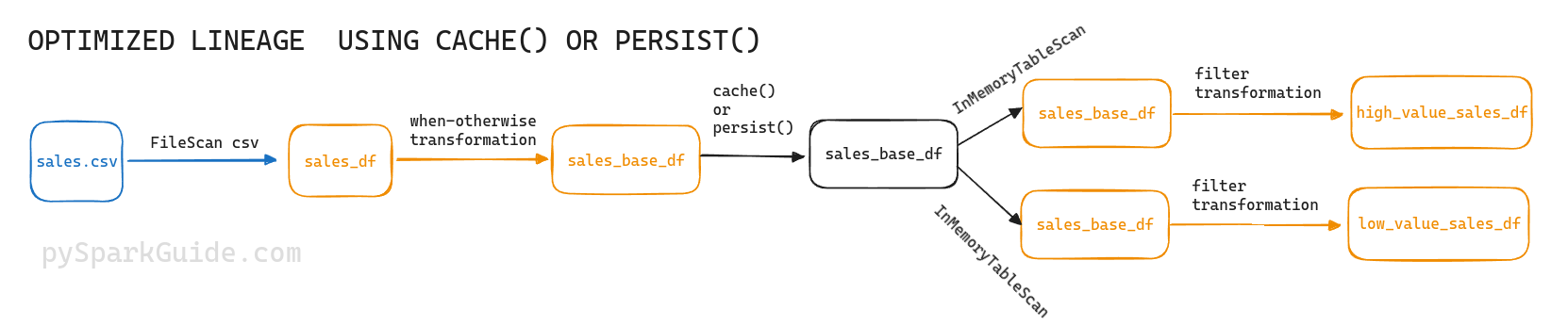
This is why we use cache() or persist(). To make spark re-use already generated dataframes, and not re-calculate them from scratch.
Calling cache() or persist() on dataframes makes spark store them for future use. If these dataframes are expensive to re-generate, this will massively speed up your spark jobs.
What to use - cache() or persist()
- Use
cache()when you want to save the dataframe only at the default storage level. - Use
persist()when you want to save the dataframe at any storage level.
So, you can just do everything using persist() itself. Still, cache() is provided for convenience, when we simply want to use the default storage level.
The default storage levels used by spark are:
- RDD - By default RDDs use the
MEMORY_ONLYstorage level - Dataset - By default datasets use the
MEMORY_AND_DISKstorage level
We don't have to think about dataset, because the dataset API is only available for Java & Scala. Not for Python.
cache()
cache()doesn't take any arguments. It simply caches the object to its default storage level.- Documentation link - pyspark.sql.DataFrame.cache
Example:
# Example - cache the dataframe dim_sales_df
dim_sales_df.cache()
persist()
persist()takes one argument - the storage level- Documentation link - pyspark.sql.DataFrame.persist
Example:
# Example - persist the dataframe dim_sales_df to the DISK_ONLY storage level
from pyspark import StorageLevel
dim_sales_df.persist(StorageLevel.DISK_ONLY)
Available storage levels
These are the storage levels available for use:
NONE- No persistenceStorageLevel.MEMORY_ONLY- Deserialize and store the dataframe into the JVM's ram (Ram allocated inspark.executor.memoryandspark.driver.memory). Deserialized data takes more storage space, but is faster.StorageLevel.MEMORY_ONLY_2- Save the dataframe in memory of current node, also save a copy in a 2nd nodeStorageLevel.MEMORY_AND_DISK- Store deserialized dataframe in JVM's memory. If it is too large for memory, serialize the excess partitions and store them on disk.StorageLevel.MEMORY_AND_DISK_2- Just likeMEMORY_AND_DISK, but also store a copy on a 2nd nodeStorageLevel.MEMORY_AND_DISK_DESER- Similar toMEMORY_AND_DISK, but only stores deserialized data.StorageLevel.DISK_ONLY- Serialize the data and store it only on diskStorageLevel.DISK_ONLY_2- Just likeDISK_ONLY, but also store a copy on a 2nd node's diskStorageLevel.DISK_ONLY_3- Just likeDISK_ONLY, but also store a copy on a 2nd and 3rd nodes' disksStorageLevel.OFF_HEAP- Experimental feature. I'm not sure if we should really use it. Stackoverflow discussion
Documentation link - pyspark.StorageLevel
Note - There are 2 more types that are exclusively available in the Scala and Java API - MEMORY_ONLY_SER and MEMORY_AND_DISK_SER. We cannot use them in pySpark.
Usage example:
from pyspark import StorageLevel
dim_sales_df.persist(StorageLevel.MEMORY_ONLY)
Notes on performance
Understanding how dataframes are saved
The data present in memory is live data. Think of it as a byte-stream.
- Serialized data will use less space than de-serialized data.
- Serialization is slow as it is very cpu-intensive. De-serialization is comparatively very fast
Data persisted in memory is persisted as it is, without requiring any further processing. However, when the data is persisted to disk - it always has to be serialized. This makes storing to disk slow as the process is both CPU intensive and I/O intensive.
Always prefer persisting/caching to memory instead of disk. Persist to disk only if truly necessary (dataframe is too large to fit into memory). Depending on lineage, many times, it could be faster to let spark re-compute the dataframe, rather than persisting it to disk and reading it back from disk.
Steps occurring while storing to disk:
- Before storing onto the disk, the data is serialized. This is an extremely CPU intensive process.
- After serialization, the serialized data is stored to disk. This is extremely I/O intensive.
Steps occurring while reading from disk:
- When reading data, the data is first read from disk onto memory, which is I/O intensive.
- The loaded data in memory is then de-serialized. This de-serialization is fast, but it still consumes some CPU and time.
Advice
Advice from real world
Avoid caching the data immediately after reading it.
Read the data, apply filters on it to reduce the number of rows, and then cache it. Without this, spark won't use dynamic partition pruning while reading the data.
Consider this example:
df = spark.read.parquet(sales_data_path)
christmas_sales_df = df_cached.filter(
(F.col("year") == 2024) & (F.col("month") == 12) & (F.col("day") == 25)
)
christmas_sales_df.write.mode("overwrite").parquet(output_data_path)
In this example - we read the data, filter it, cache it, write out the cached df
In this case, spark used dynamic partition pruning to skip over irrelevant partition files. Internally, what happened was:
- Spark saw the partitions/files that need to be read
- Spark saw the filter condition
- Spark decided to read only relevant partitions, skipping the reads of un-necessary files
- Spark wrote the df
Now, suppose the df is cached immediately after reading
df = spark.read.parquet(sales_data_path)
df_cached = df.cache() # premature caching
christmas_sales_df = df_cached.filter(
(F.col("year") == 2024) & (F.col("month") == 12) & (F.col("day") == 25)
)
christmas_sales_df.write.mode("overwrite").parquet(output_data_path)
In this case, spark won't do dynamic partition pruning, and read the entire dataset. Internally, what happened was:
- Spark saw the partitions/files that need to be read
- Spark saw the cache() action. So it read all the data files, and cached them
- Spark filtered the dfcached to get christmassales_df
- Spark saved christmassalesdf
In this case, spark couldn't perform dynamic partition pruning, and ended up reading the entire dataset. This was because spark was forced to read all the data due to the cache() action. So even though there is a filter in the next step, all the data had to be read in the current step.
Premature caching can prevent spark from applying read-time optimizations like
- Skipping files read using dynamic partition pruning
- Skipping columns read from files using projection pushdown
- Skipping parquet rowsets read using predicate pushdown
This is horribly inefficient in the real world, where datasets can be massive and we rely a lot on dynamic partition pruning.
So - read data, filter it, and once the smaller dataset is ready, only then cache it.
Advice from the documentation
(I've copy-pasted this section from the documentation)
Documentation source link - Which Storage Level to Choose?
Spark’s storage levels are meant to provide different trade-offs between memory usage and CPU efficiency. We recommend going through the following process to select one:
- If your RDDs fit comfortably with the default storage level (
MEMORY_ONLY), leave them that way. This is the most CPU-efficient option, allowing operations on the RDDs to run as fast as possible. - (Java and Scala) - If not, try using
MEMORY_ONLY_SERand selecting a fast serialization library to make the objects much more space-efficient, but still reasonably fast to access. - Don’t spill to disk unless the functions that computed your datasets are expensive, or they filter a large amount of the data. Otherwise, recomputing a partition may be as fast as reading it from disk.
- Use the replicated storage levels if you want fast fault recovery (e.g. if using Spark to serve requests from a web application). All the storage levels provide full fault tolerance by recomputing lost data, but the replicated ones let you continue running tasks on the RDD without waiting to recompute a lost partition.
Misc notes from the source code
Here is the definition of the StorageLevel class in the spark source code:
Path: /spark/python/pyspark/storagelevel.py
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
__all__ = ["StorageLevel"]
from typing import Any, ClassVar
class StorageLevel:
"""
Flags for controlling the storage of an RDD. Each StorageLevel records whether to use memory,
whether to drop the RDD to disk if it falls out of memory, whether to keep the data in memory
in a JAVA-specific serialized format, and whether to replicate the RDD partitions on multiple
nodes. Also contains static constants for some commonly used storage levels, MEMORY_ONLY.
Since the data is always serialized on the Python side, all the constants use the serialized
formats.
"""
NONE: ClassVar["StorageLevel"]
DISK_ONLY: ClassVar["StorageLevel"]
DISK_ONLY_2: ClassVar["StorageLevel"]
DISK_ONLY_3: ClassVar["StorageLevel"]
MEMORY_ONLY: ClassVar["StorageLevel"]
MEMORY_ONLY_2: ClassVar["StorageLevel"]
MEMORY_AND_DISK: ClassVar["StorageLevel"]
MEMORY_AND_DISK_2: ClassVar["StorageLevel"]
OFF_HEAP: ClassVar["StorageLevel"]
MEMORY_AND_DISK_DESER: ClassVar["StorageLevel"]
def __init__(
self,
useDisk: bool,
useMemory: bool,
useOffHeap: bool,
deserialized: bool,
replication: int = 1,
):
self.useDisk = useDisk
self.useMemory = useMemory
self.useOffHeap = useOffHeap
self.deserialized = deserialized
self.replication = replication
def __repr__(self) -> str:
return "StorageLevel(%s, %s, %s, %s, %s)" % (
self.useDisk,
self.useMemory,
self.useOffHeap,
self.deserialized,
self.replication,
)
def __str__(self) -> str:
result = ""
result += "Disk " if self.useDisk else ""
result += "Memory " if self.useMemory else ""
result += "OffHeap " if self.useOffHeap else ""
result += "Deserialized " if self.deserialized else "Serialized "
result += "%sx Replicated" % self.replication
return result
def __eq__(self, other: Any) -> bool:
return (
isinstance(other, StorageLevel)
and self.useMemory == other.useMemory
and self.useDisk == other.useDisk
and self.useOffHeap == other.useOffHeap
and self.deserialized == other.deserialized
and self.replication == other.replication
)
StorageLevel.NONE = StorageLevel(False, False, False, False)
StorageLevel.DISK_ONLY = StorageLevel(True, False, False, False)
StorageLevel.DISK_ONLY_2 = StorageLevel(True, False, False, False, 2)
StorageLevel.DISK_ONLY_3 = StorageLevel(True, False, False, False, 3)
StorageLevel.MEMORY_ONLY = StorageLevel(False, True, False, False)
StorageLevel.MEMORY_ONLY_2 = StorageLevel(False, True, False, False, 2)
StorageLevel.MEMORY_AND_DISK = StorageLevel(True, True, False, False)
StorageLevel.MEMORY_AND_DISK_2 = StorageLevel(True, True, False, False, 2)
StorageLevel.OFF_HEAP = StorageLevel(True, True, True, False, 1)
StorageLevel.MEMORY_AND_DISK_DESER = StorageLevel(True, True, False, True)