Delta isn't a storage format. It is like a storage library that gives you a mechanism to get ACID guarantees over your file based data storage. It uses a combination of
- parquet files to store data
- json files to store activity & transaction logs, track data files etc
To reliably maintain data in tabular format within your data lakes, you have 2 options -
- Use Delta by Databricks
- Use Apache iceberg
Both options are open source. Databricks maintains and works to propagate delta (naturally, they have an incentive to do it, as they get to create and control the industry standard).
Use delta to convert the raw data in your data lake's bronze layer, into processed tables in your silver layer, to build your data warehouse.
Delta enables the transition from data lake to data warehouse due to its tabular storage, inherent support for ACID, and rich support for SQL based operations.
Read Delta
Read latest version of data:
sales_df = (
spark
.read
.format("delta")
.load("/data/sales/")
)
Read a specific version of data
You can tell which past version of the data you want to read by -
- Specifying the exact version number
- Specifying a timestamp
Load data of version number 10 :
sales_df = (
spark
.read
.format("delta")
.option("versionAsOf", 10)
.load("/data/sales/")
)
Load data from the snapshot at 2023/12/11 :
sales_df = (
spark
.read
.format("delta")
.option("timestampAsOf", "2023/12/11") # give timestamp string here
.load("/data/sales/")
)
manually set schema
Since the underlying data format is parquet, which already stores metadata about the datatype of columns, there is no inferSchema option.
If you want to override the schema that spark got from the parquet file's metadata section, and set your own datatypes, you can do it manually.
There are 2 ways to set schema manually:
- Using DDL string
- Programmatically, using
StructTypeandStructField
Set schema using DDL string
This is the recommended way to define schema, as it is the easier and more readable option. These datatypes we use in the string are the Spark SQL datatypes.
The format is simple. It is a string-csv of the dataframe's every column name & datatype.
schema_ddl_string = "<column_name> <data type>, <column_name> <data type>, <column_name> <data type>"
sales_schema_ddl = """year INT, month INT, day INT, amount DECIMAL"""
sales_df = (
spark
.read
.format("delta")
.schema(sales_schema_ddl) # set schema
.load("/data/sales/")
)
The datatypes you can use for DDL string are:
| Data type | SQL name |
|---|---|
| BooleanType | BOOLEAN |
| ByteType | BYTE, TINYINT |
| ShortType | SHORT, SMALLINT |
| IntegerType | INT, INTEGER |
| LongType | LONG, BIGINT |
| FloatType | FLOAT, REAL |
| DoubleType | DOUBLE |
| DateType | DATE |
| TimestampType | TIMESTAMP, TIMESTAMP_LTZ |
| TimestampNTZType | TIMESTAMP_NTZ |
| StringType | STRING |
| BinaryType | BINARY |
| DecimalType | DECIMAL, DEC, NUMERIC |
| YearMonthIntervalType | INTERVAL YEAR, INTERVAL YEAR TO MONTH, INTERVAL MONTH |
| DayTimeIntervalType | INTERVAL DAY, INTERVAL DAY TO HOUR, INTERVAL DAY TO MINUTE, INTERVAL DAY TO SECOND, INTERVAL HOUR, INTERVAL HOUR TO MINUTE, INTERVAL HOUR TO SECOND, INTERVAL MINUTE, INTERVAL MINUTE TO SECOND, INTERVAL SECOND |
| ArrayType | ARRAY |
| StructType | STRUCT Note: ‘:’ is optional. |
| MapType | MAP |
Source - Spark SQL - Supported Data Types
Set schema programmatically using python API functions
Here is what the code looks like. I've explained it below the code snippet.
from pyspark.sql import types as T
sales_schema_struct = T.StructType(
[
T.StructField("year", T.IntegerType()),
T.StructField("month", T.IntegerType()),
T.StructField("day", T.IntegerType()),
T.StructField("amount", T.DecimalType()),
]
)
sales_df = (
spark
.read
.format("delta")
.schema(sales_schema_struct) # set schema
.load("/data/sales/")
)
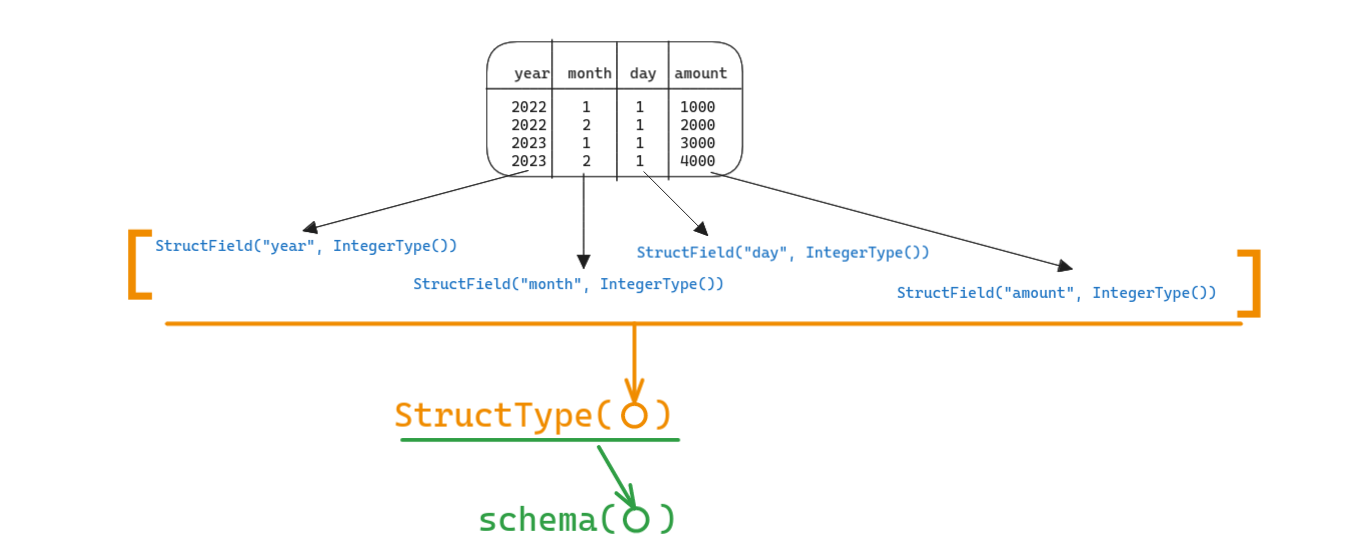
Explanation:
We define a column's datatype using the StructField() method. To define the schema of the entire dataframe, we -
- Create a
StructField("column_name", DataType())that defines datatype of one column of the dataframe - Create a list of
StructField(), to define the data type of every column in the dataframe - Pass list of
StructFields into aStructType() - Pass the
StructType()object to theschema()method ofDataFrameReader.read
The datatypes you can use in StructField() are:
| Data type | Value type in Python | API to access or create a data type |
|---|---|---|
| ByteType | int or long Note: Numbers will be converted to 1-byte signed integer numbers at runtime. Please make sure that numbers are within the range of -128 to 127. |
ByteType() |
| ShortType | int or long Note: Numbers will be converted to 2-byte signed integer numbers at runtime. Please make sure that numbers are within the range of -32768 to 32767. |
ShortType() |
| IntegerType | int or long | IntegerType() |
| LongType | long Note: Numbers will be converted to 8-byte signed integer numbers at runtime. Please make sure that numbers are within the range of -9223372036854775808 to 9223372036854775807. Otherwise, please convert data to decimal.Decimal and use DecimalType. |
LongType() |
| FloatType | float Note: Numbers will be converted to 4-byte single-precision floating point numbers at runtime. |
FloatType() |
| DoubleType | float | DoubleType() |
| DecimalType | decimal.Decimal | DecimalType() |
| StringType | string | StringType() |
| BinaryType | bytearray | BinaryType() |
| BooleanType | bool | BooleanType() |
| TimestampType | datetime.datetime | TimestampType() |
| TimestampNTZType | datetime.datetime | TimestampNTZType() |
| DateType | datetime.date | DateType() |
| DayTimeIntervalType | datetime.timedelta | DayTimeIntervalType() |
| ArrayType | list, tuple, or array | ArrayType(elementType, [containsNull]) Note:The default value of containsNull is True. |
| MapType | dict | MapType(keyType, valueType, [valueContainsNull]) Note:The default value of valueContainsNull is True. |
| StructType | list or tuple | StructType(fields) Note: fields is a Seq of StructFields. Also, two fields with the same name are not allowed. |
| StructField | The value type in Python of the data type of this field (For example, Int for a StructField with the data type IntegerType) |
StructField(name, dataType, [nullable]) Note: The default value of nullable is True. |
Source - Spark SQL - Supported Data Types
write delta
Write as files
(
sales_df
.write
.format("delta")
.mode("overwrite")
.save("/data/sales")
)
Save as a spark table
(
sales_df
.write
.format("delta")
.mode("overwrite")
.save("/data/sales")
)
Partition written data on specific columns
(
sales_df
.write
.format("delta")
.partitionBy("year", "month", "date")
.mode("overwrite")
.save("/data/sales")
)
Suppose you want to change the partition columns.
Eg - Currently saved data is partitioned only by year, but you want to partition by year, month and day
You can override the partition scheme using the overwriteSchema option. There is no need to drop existing table and create new one.
(
sales_df
.write
.format("delta")
.mode("overwrite")
.option("overwriteSchema", "true")
.partitionBy("year", "month", "date")
.option("path", "data/sales")
.saveAsTable("sales")
)
Bucket written data on specific columns
You cannot manually bucket data while using Delta. You simply don't need to.
Notes
replaceWhere
You can also selectively replace rows that match specific conditions using the replaceWhere option, using a sql expression in the replaceWhere option.
Eg - Only replace rows of First month of 2023:
(
sales_df
.write
.format("delta")
.mode("overwrite")
.option("replaceWhere", "year == 2023 AND month == 1")
.option("path", "data/sales")
.saveAsTable("sales")
)
Bucketing cannot be done for delta tables
For optimization, all you can do is use z-ordering.
Databricks Community support answer
We use bucketing to sort data in storage, so that the spark operations will be faster after loading it (by preventing shuffles). In this case, z-ordering does the same thing for you, on the entire table. So there is no need to do bucketing anyways.
If you think about it, delta tries to be a pretty hands-off format. It nudges you to just create tables and stop bothering about the structure of files etc within the table. In this case - Instead of bucketing, setting number of buckets etc, just do z-ordering and reduce your mental load.
Need more performance? run OPTIMIZE .
That's it. Enjoy.